
Local Code Execution
Functions in high-level languages like C are compiled into procedures in assembly. They add a level of indirection that frees us from having to think about memory addresses.
Methods and polymorphism in object-oriented languages like Java add another level of indirection that frees us from having to think about the specific variant of a set of similar functions.
Despite these indirections, methods are basically still procedure calls, telling the computer to switch execution flow from one memory location to another. All of this happens in the same process running on the same computer.
Remote Code Execution
This is fundamentally different from switching execution to another process or another computer. Especially the latter is very different, as the other computer may not even have the same operating system through which programs access memory.
It is therefore no surprise that mechanisms of remote code execution that try to hide this difference as much as possible, like RMI or SOAP, have largely failed. Such technologies employ what is known as Remote Procedure Calls (RPCs).
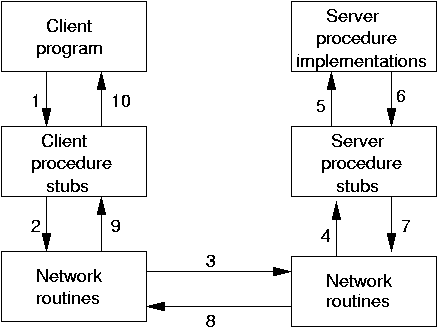 One reason we must distinguish between local and remote procedure calls is that RPCs are a lot slower.
One reason we must distinguish between local and remote procedure calls is that RPCs are a lot slower.
For most practical applications, this changes the nature of the calls you make: you’ll want to make less remote calls that are more coarsely grained.
Another reason is more organizational than technical in nature.
When the code you’re calling lives in another process on another computer, chances are that the other process is written and deployed by someone else. For the two pieces of code to cooperate well, some form of coordination is required. That’s the price we pay for coupling.
Coordinating Change With Interfaces
We can also see this problem in a single process, for instance when code is deployed in different jar files. If you upgrade a third party jar file that your code depends on, you may need to change your code to keep everything working.
Such coordination is annoying. It would be much nicer if we could simply deploy the latest security patch of that jar without having to worry about breaking our code. Fortunately, we can if we’re careful.
 Interfaces in languages like Java separate the public and private parts of code.
Interfaces in languages like Java separate the public and private parts of code.
The public part is what clients depend on, so you must evolve interfaces in careful ways to avoid breaking clients.
The private part, in contrast, can be changed at will.
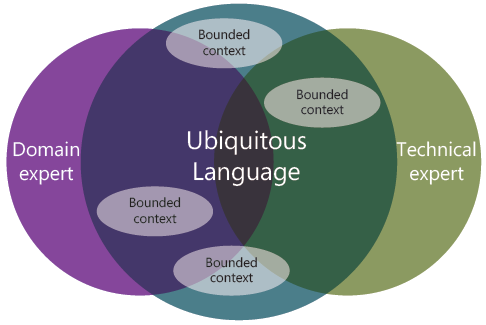
From Interfaces to Services
In OSGi, interfaces are the basis for what are called micro-services. By publishing services in a registry, we can remove the need for clients to know what object implements a given interface. In other words, clients can discover the identity of the object that provides the service. The service registry becomes our entry point for accessing functionality.
There is a reason these interfaces are referred to as micro-services: they are miniature versions of the services that make up a Service Oriented Architecture (SOA).
A straightforward extrapolation of micro-services to “SOA services” leads to RPC-style implementations, for instance with SOAP. However, we’ve established earlier that RPCs are not the best way to invoke remote code.
Enter REST.
RESTful Services
 Representational State Transfer (REST) is an architectural style that brings the advantages of the Web to the world of programs.
Representational State Transfer (REST) is an architectural style that brings the advantages of the Web to the world of programs.
There is no denying the scalability of the Web, so this is an interesting angle.
Instead of explaining REST as it’s usually done by exploring its architectural constraints, let’s compare it to micro-services.
A well-designed RESTful service has a single entry point, like the micro-services registry. This entry point may take the form of a home resource.
We access the home resource like any other resource: through a representation. A representation is a series of bytes that we need to interpret. The rules for this interpretation are given by the media type.
Most RESTful services these days serve representations based on JSON or XML. The media type of a resource compares to the interface of an object.
Some interfaces contain methods that give us access to other interfaces. Similarly, a representation of a resource may contain hyperlinks to other resources.
Code-Based vs Data-Based Services
 The difference between REST and SOAP is now becoming apparent.
The difference between REST and SOAP is now becoming apparent.
In SOAP, like in micro-services, the interface is made up of methods. In other words, it’s code based.
In REST, on the other hand, the interface is made up of code and data. We’ve already seen the data: the representation described by the media type. The code is the uniform interface, which means that it’s the same (uniform) for all resources.
In practice, the uniform interface consists of the HTTP methods GET, POST, PUT, and DELETE.
Since the uniform interface is fixed for all resources, the real juice in any RESTful service is not in the code, but in the data: the media type.
Just as there are rules for evolving a Java interface, there are rules for evolving a media type, for example for XML-based media types. (From this it follows that you can’t use XML Schema validation for XML-based media types.)
Uniform Resource Identifiers
So far I haven’t mentioned Uniform Resource Identifiers (URIs). The documentation of many so-called RESTful services may give you the impression that they are important.
 However, since URIs identify resources, their equivalent in micro-services are the identities of the objects implementing the interfaces.
However, since URIs identify resources, their equivalent in micro-services are the identities of the objects implementing the interfaces.
Hopefully this shows that clients shouldn’t care about URIs. Only the URI of the home resource is important.
The representation of the home resource contains links to other resources. The meaning of those links is indicated by link relations.
Through its understanding of link relations, a client can decide which links it wants to follow and discover their URIs from the representation.
Versions of Services
 As much as possible, we should follow the rules for evolving media types and not introduce any breaking changes.
As much as possible, we should follow the rules for evolving media types and not introduce any breaking changes.
However, sometimes that might be unavoidable. We should then create a new version of the service.
Since URIs are not part of the public interface of a RESTful API, they are not the right vehicle for relaying version information. The correct way to indicate major (i.e. non-compatible) versions of an API can be derived by comparison with micro-services.
Whenever a service introduces a breaking change, it should change its interface. In a RESTful API, this means changing the media type. The client can then use content negotiation to request a media type it understands.
What Do You Think?
 Literature explaining how to design and document code-based interfaces is readily available.
Literature explaining how to design and document code-based interfaces is readily available.
This is not the case for data-based interfaces like media types.
With RESTful services becoming ever more popular, that is a gap that needs filling. I’ll get back to this topic in the future.
How do you design your services? How do you document them? Please share your ideas in the comments.
 Last time, I wrote about
Last time, I wrote about  If your organization doesn’t have something like our PSO, you can look elsewhere. (And if it does, you should look outside too!)
If your organization doesn’t have something like our PSO, you can look elsewhere. (And if it does, you should look outside too!) You may think you know very little yet, but even then it’s valuable to share.
You may think you know very little yet, but even then it’s valuable to share.
 The SaaS platform I’m working on has a RESTful interface that accepts XML payloads.
The SaaS platform I’m working on has a RESTful interface that accepts XML payloads. We could rely on
We could rely on  If we can’t use schema validation, then what about using JSR 303
If we can’t use schema validation, then what about using JSR 303 
 In this approach, primitive types are replaced with value objects. (Some people even
In this approach, primitive types are replaced with value objects. (Some people even  Last time, I
Last time, I  In JavaScript, an object represents a table relating names to values.
In JavaScript, an object represents a table relating names to values. The first issue with the JavaBean-like code is that it’s built on the mistaken assumption that the
The first issue with the JavaBean-like code is that it’s built on the mistaken assumption that the  Every object is associated with a prototype object. The
Every object is associated with a prototype object. The  Here we see some very powerful things at work.
Here we see some very powerful things at work. I freaked out when I first realized that any code can change any property and that different instances of a “class” can have different methods.
I freaked out when I first realized that any code can change any property and that different instances of a “class” can have different methods. At
At  Of course, this is only a small step and a lot more work needs to be done before we really have an FDE.
Of course, this is only a small step and a lot more work needs to be done before we really have an FDE. Maybe I’m just doing it wrong. I’d appreciate any hints in the comments.
Maybe I’m just doing it wrong. I’d appreciate any hints in the comments.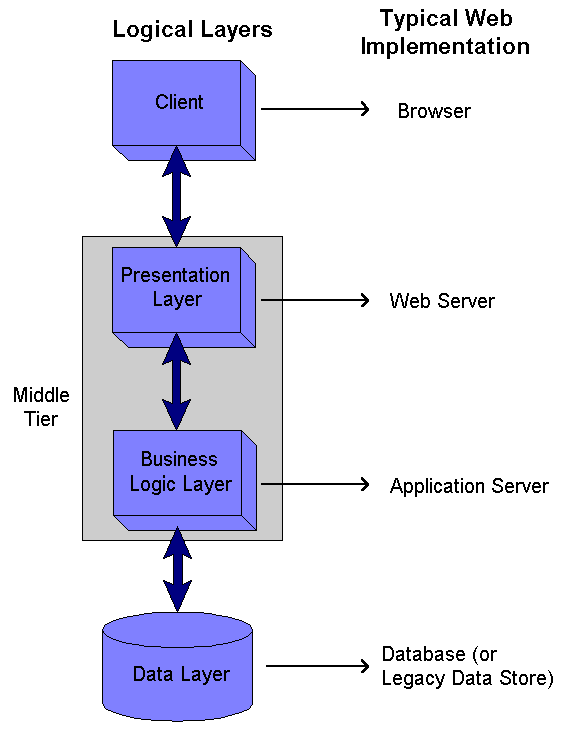

You must be logged in to post a comment.